
手元の仮想サーバに本番環境を再現しようとしたときの出来事、第三弾。
データベースのコピーやプラグインのバックアップを移す方法ではなく、インポート機能を使いました。
ところが、インポートした側の記事ではレイアウトが壊れる現象が発生。
この問題についてツイートしたところ、同じトラブルに遭っていた人がいたので、記事にすることにしました。
その原因がCDATAセクションだった、というところから「なぜCDATAセクションが存在するのか」「どうすれば解決できるのか」を見ていきます。
トラブルの詳細
まず、どんな問題か画像を見てもらったほうが早いでしょう(Fig1)。
これは以前のブログテーマですが、見出しを挟んだ上下の文章で見た目が異なります。
クラシックエディタで書かれた文章にはPタグが自動で挿入されますが、下の文章には挿入されず、CSSの処理が行われていません。
新しいテーマでは記事の部分が白い背景のボックスに包まれていますが、それが途中で閉じてしまったこともありました。
記事を囲んでいるボックスが閉じたにも関わらず、その後ろに残りの文章が続くのは明らかに期待する処理ではありません。

エディタ上でHTMLを見てみると、<!CDATA[ ]]>というタグのようなものが挿入されていることがわかります。
同時に、H2タグが壊されています。
これによってCSSは正常に処理されず、レイアウトを崩したと思われます。
なお、このトラブルは従来の「クラシックエディタ」で書かれた記事が影響を受けます。
WordPress 5.0 (Gutenberg)で実装されたブロックエディター(形式)で書かれた記事では、本文の前後にCDATAの開始と終了のコードが追加されるだけで、影響は少ないです。
WordPressのインポート機能を使うとなぜか挿入される”CDATA”。挿入のされかたも滅茶苦茶で、テスト環境でレイアウトがぶっ壊れる原因になってる。(‘A`) pic.twitter.com/JTRGUFg2Vo
— chromitz (@chromitz) 2019年4月19日
CDATAとは
わかっているのは「CDATA」というキーワードだけ。
しかし、WordPressとセットで検索してもほしい情報はヒットしませんでした。
となれば、唯一の手がかりであるCDATAから調べるしかないでしょう。
調べてみると、概念は簡単に理解できました。
HTMLなどのタグ(マークアップ)が、XMLのタグに影響を与えないようにしているんですね。
見た目はHTMLタグのようですが、呼び方は「セクション」の模様。
マークアップ専用の記号であって、通常の文字として扱う特例的な部分をつくることができる。これを、CDATAセクションという。
XML用語事典 [CDATAセクション]
CDATAセクションは、<![CDATA[という文字列で始まり、]]>という文字列で終わる。CDATAセクションの内部には、XMLで利用可能な文字をすべて記述することができる。唯一の例外は]]>という文字列だけで、これを記述することはできない。記述しても、CDATAセクションの終了を示すと解釈されてしまう。
CDATA は Character Data の意味で、読んで字のごとく文字データを表します。
CDATA (文字データ) _ ばけらの HTML リファレンス(未完成)
(略)
・文字参照は展開されず、そのままの文字として扱われる。& と書けば、それはそのまま & という文字列として扱われます。
・マークアップの記号はそのまま文字として扱われる。< や > などは単なる文字と見なされます。<!– –> を書いても、中身は無視されません。
それから、ETAGO が出現した時点で CDATA が終了することに注意してください。ETAGO とは「終了タグ開始区切り子」のことで、HTML では </ という文字列です。つまり、CDATA の中に </ を書くことはできません。そういうわけで、SCRIPT の中にも </ を書くことはできません。
XMLの用語辞典に載っているということは、CDATAはXMLの関係者ということになります。
ここで、思い当たることがあります。
エクスポートされたファイル形式はXMLであるということ。
なるほど。CDATAセクションが挿入されたのは、「XMLファイルでエクスポートした」から。
「何もしてないけど壊れた」わけではないってことですね。
エクスポートしたXMLファイルを覗いてみる
エクスポートしたファイルを正常にインポートするために、手を加えたり、中を読もうとしたことはありませんでした。
ヒントを求めてファイルを読んでみると、WordPressのたくさんのデータがタグに囲まれています。
これら要素は20種類ほどあり、エクスポートしたXMLファイルにも同じように書かれています。
記事の本文が記述されている部分は<content:encoded></content:encoded>タグに内包されており、本文が持っているタグ・マークアップを無害化するためにCDATAセクションに囲まれています(Fig2)。

CDATAセクションのトラブルを振り返ってみる
エクスポートされた記事の本文は、XMLの<content:encoded></content:encoded>タグで包まれます。
そして、本文が持つマークアップを無害化するためにCDATAセクションに記述されることがわかりました。
このことから、XMLファイルをインポートしたとき<content:encoded></content:encoded>の中身が記事の本文として移されることが推測できました。
もう一歩踏み込むと、<content:encoded></content:encoded>タグに囲まれた「<!CDATA[]]>」という文字列すらも本文の一部としてインポートされていることに気づきます。
レイアウトが崩れる原因は中途半端なコメントアウト
冒頭のツイートはWordPressのエディタをHTML表示にしたものです。
ここまでの話だとCDATAセクションに囲まれ、マークアップが無害化された結果だと思うでしょう。
私もそうだと思っていました。
この記事を書くにあたって裏付けのためのスクリーンショットを撮ったところ、CDATAセクションがコメントアウトされていることに気づきました。
(ChromiumをベースにしたVivaldiブラウザにて。)
確認のためにWordPressのエディタ、出力されたHTMLのソース、ブラウザが解釈したHTMLを、順番にお見せしたいと思います。
WordPressのエディタ上のHTML
ツイートで示した画像のように、CDATAセクションが目立ちます(Fig3)。HTMLのコメントアウト文は存在しません。

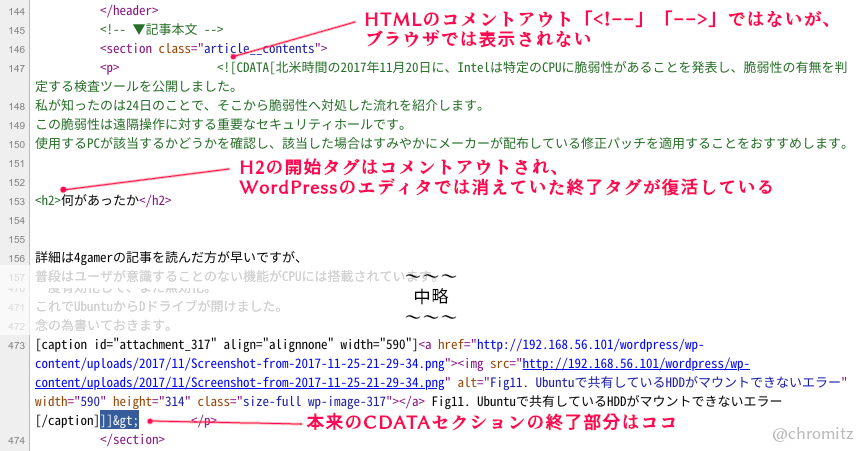
出力されたWebページのソースコード
ページのソースを表示(Ctrl + U)してみると、コメントアウト文ではないのに緑文字でコメントアウト扱いになっています(Fig4)。
CDATAの終了部分は見当たりませんが、エディタ上では消滅してたH2の終了タグが復活しています。
末尾のエスケープされた終了部分はエディタの時点と変わりません。
ブラウザのデベロッパーツールで見るHTML
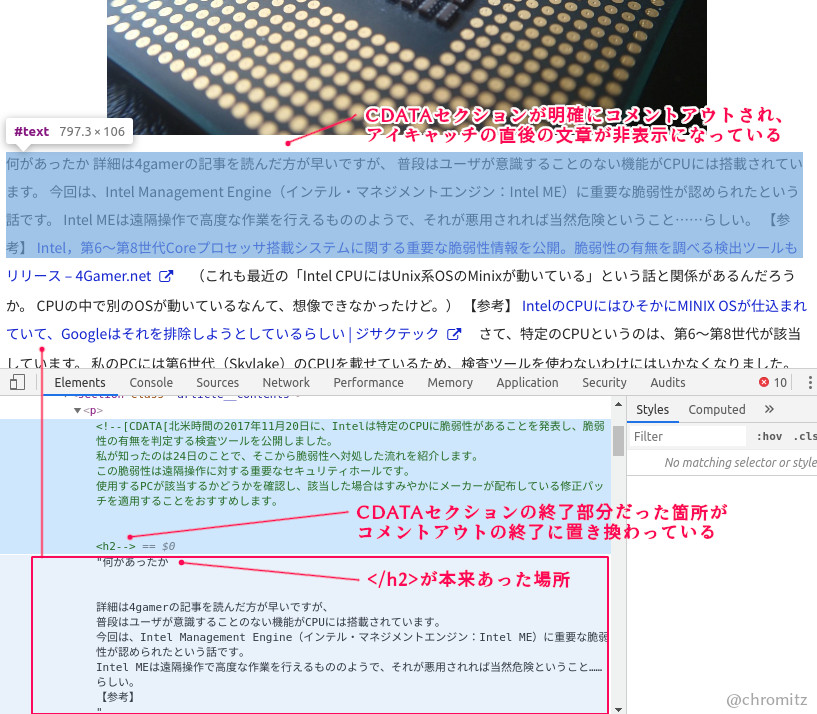
デベロッパーツール(「要素を検証」)では、コメントアウト文が明確に記述されています(Fig5)。
H2タグに食い込んでいたCDATAセクションの終了部分( ]]> )が、コメントアウトの終了コード( –> )に置き換わっています。
エディタで編集している時点ではコメントアウトされていないので、WordPressのシステムを通してHTMLが整形されたときに「HTMLでは不適切なCDATAセクション」がコメントアウトされたのでしょう。
最近のブラウザは賢い。
なぜ、CDATAの終了位置が変わるのか
レイアウトが崩れる原因は判明しましたが、ふたつの疑問が残っています。
一つは、なぜCDATAセクションの終了位置が変わったのか。
最初に述べたように、このトラブルは従来のクラシックエディタ(形式)で書かれた記事に影響があります。
しかし、レイアウトが崩れた記事のHTMLはCDATAのコメントアウトの終了位置が、なぜか本文の途中に変わっています。
本文を包み込むように、最初と最後に記述されていたのに。
これはインポートされた後、WordPressのエディタ上ですでに発生しています。
この原因は、正直わかりませんでした。
CDATAとWordPressのキーワードではググってもヒットせず、関連性が見いだせませんでした。
また、上で引用した中に、「ETAGO( </ )があればCDATAセクションは終了する」とありますが、これはHTML4の話。
仮に考慮しても、H2の終了タグの位置ならまだしも、開始タグでセクションが終了するのはおかしい。
二つめは、CDATAセクションがなぜコメントアウトされたか・置き換えられたか。
Mozzilaのドキュメントでは「HTML内でCDATAセクションを用いることは適切でない」としています。
(スクリーンショットはFirefoxではなくVivaldiですが)HTMLでの使用は不適切だから、ブラウザ側がコメントアウトした可能性が考えられます。
CDATA セクションは(非表示のものを除き)HTML 内で使用されるべきではないことに注意してください。XML でのみ使用可能です。
CDATASection – Web API _ MDN
CDATAセクションが残るインポート機能は正しいか?
そもそも、インポートした時点でCDATAセクションは不要になります。
XMLファイルでは構造を壊さないために必要でしたが、なぜ記事の一部としてインポートされるのでしょうか。
調べてみると、XMLからデータを取り出すPHPの関数に、特定の引数を渡すことでCDATAを除去できるらしい。
WordPressがこの関数を使っているかどうか未確認ですが、CDATAの除去を実現する方法は存在します。
変数「$xml」に「file_get_contents」を使って読み込んだデータを格納。
simplexml_load_stringを使ってCDATAで囲まれたデータを扱う時には「LIBXML_NOCDATA」を指定。他にも「LIBXMLパラメーター」を積極的に使うといい感じでした _ 今村だけがよくわかるブログ
「simplexml_load_string」引数を指定。第1引数に変数「$xml」、第2引数に「SimpleXMLElement」、第3引数に「LIBXML_NOCDATA」を指定。
※「simplexml_load_string」は引数ではなく関数。(「simplexml_load_string」関数に引数を指定……と書きたかったんだろう)
WordPressはオープンソースだから、その知名度からプログラムの間違いは限りなく少ないと思うが……。
あまりに情報がないということは、ユーザが少なくて報告が届かないか、その実装が正しいということになる。
インポートの仕組みに手を加えることができれば解決するかもしれないが、のぞみ薄でしょう。(問題提起するには知識や人脈が足りてない)
となると、CDATAを使わない=XML化しない方法でブログのデータを移すことになります。
データベースをそのままコピーしたり、保存したバックアップから復元するようなプラグインを使うのが現実的です。
まとめ
- XMLでエクスポートするとタグやコードを無力化するためにCDATAセクションが記述される
- (現時点で)インポートすると、CDATAセクションの開始と終了のコードも「記事の一部として」扱われる
- CDATAセクションのコードはWordPressを通してコメントアウトされる
- クラシックエディタ(形式)では、なぜかCDATAセクションの終了位置が本文中に割り込まれ、中途半端にコメントアウトされる
- ブロックエディタ(形式)では、本文の前後にCDATAセクションのブロックが追加されるだけで済む
- 中途半端なコメントアウトによりHTMLの構造が壊され、CSSが正常に処理されずにレイアウトが崩れる原因になる
- これらを回避するには、XMLでインポートしない方法を用いる